
You’ve just parked your car. Google Maps offers to record your current location so you can find where you parked your car. It also lets you note how much parking time you have available.
Sharing this data allows Google Maps to provide you with a small but valuable service: you can quickly find your car and avoid having to pay a fine.
For you that data has a limited shelf-life. It’s useful to know where you are currently parked, but much less useful to know where you were parked last week.
But that data has much more value to Google because it can be combined with the data from everyone else who uses the same feature. When aggregated that data will tell them:
- The location of all the parking spaces around the world
- Which parking spaces are most popular
- Whether those parking spaces are metered (or otherwise time-limited)
- Which parking spaces will be become available in the next few hours
- When combined with other geographic data, it can tell them the places where people usually park when they visit other locations, e.g. specific shops or venues
- …etc
That value only arises when many data points are aggregated together. And that data remains valuable for a much longer period.
With access to just your individual data point Google can offer you a simple parking reminder service. But with access to the aggregate data points they can extract further value. For example by:
- Improving their maps, using the data points to add parking spaces or validate those that they may already know about
- Suggesting a place to park as people plan a trip into the same city
- Creating an analytics solution that provides insight into where and when people park in a city
- …etc
The term data asymmetry refers to any occasion when there a disparity in access to data. In all cases this results in the data steward being able to unlock more value than a contributor.
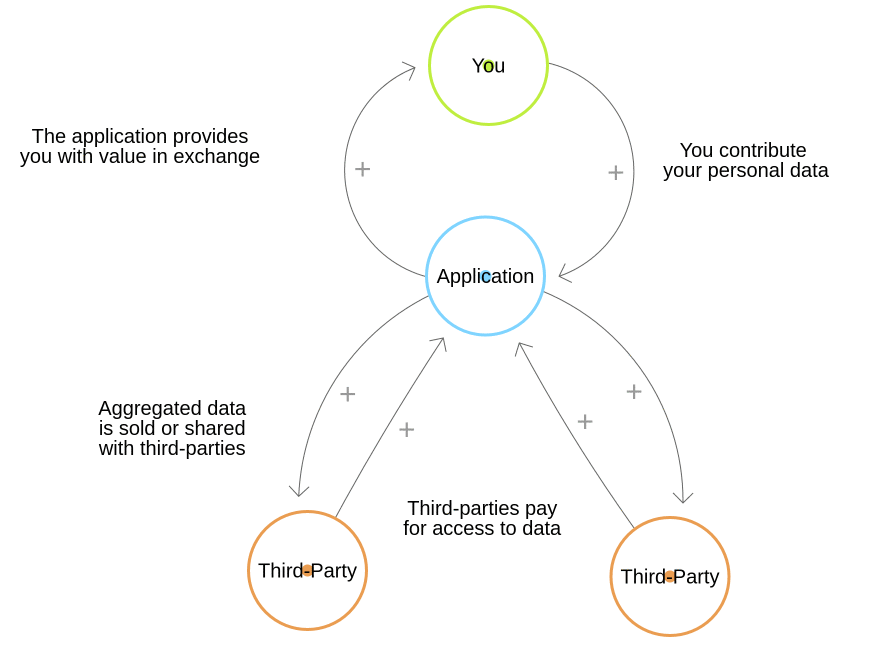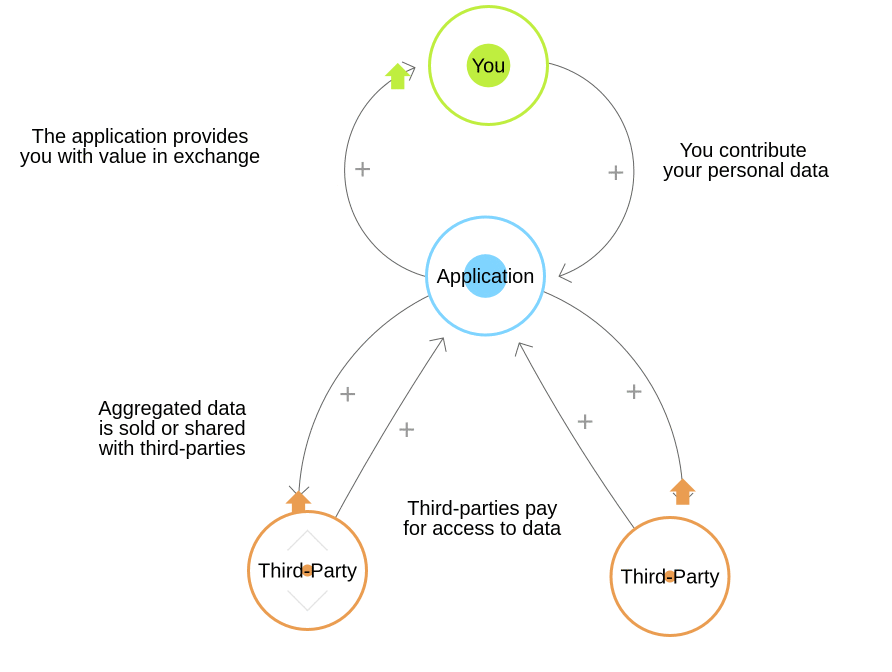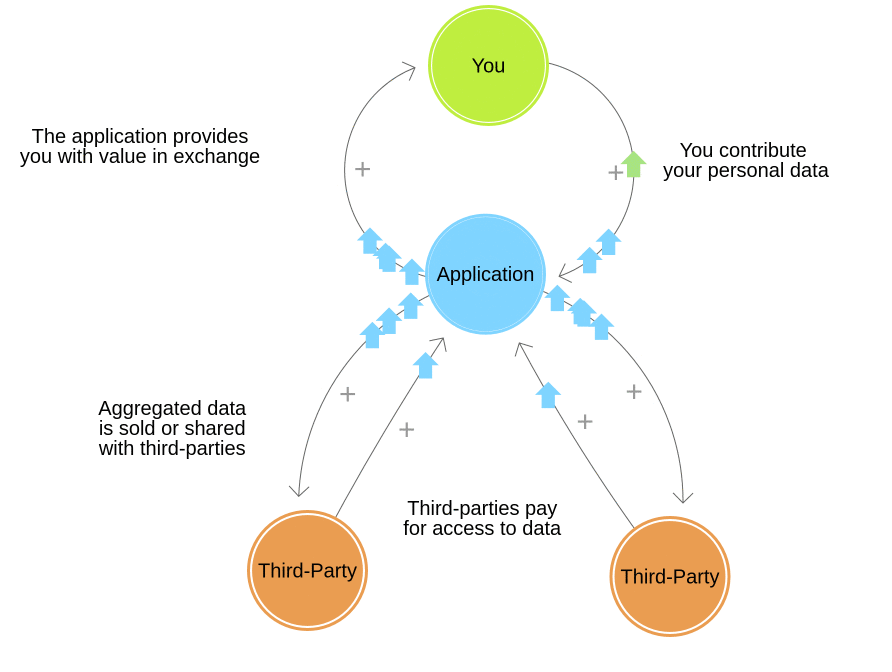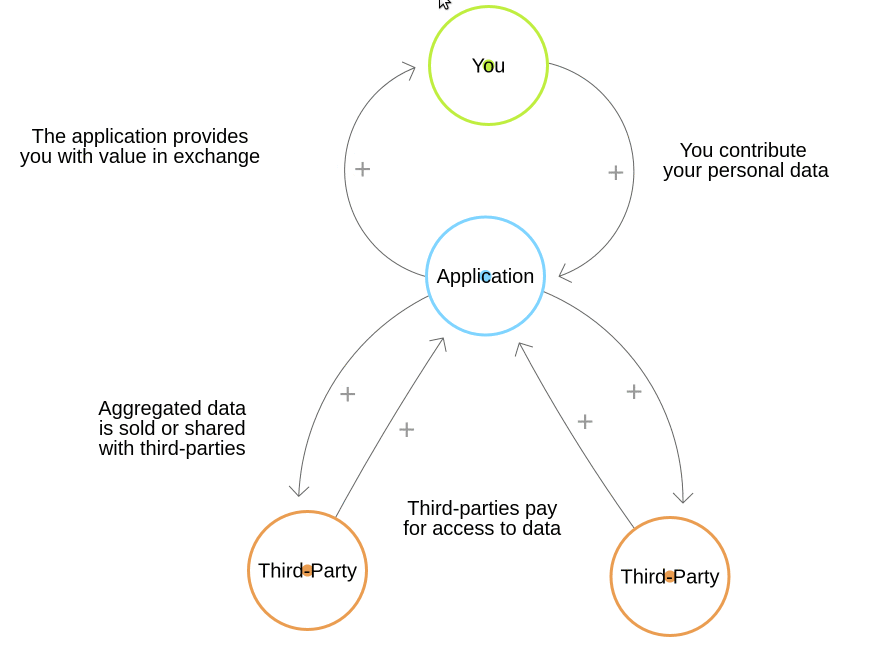
When does data asymmetry occur?
Broadly, data asymmetry occurs in almost every single digital service or application. Anyone running an application automatically has access to more information than its users. In almost all cases there will be a database of users, content or transaction histories.
Data asymmetry, and the resulting imbalances of power and value, are most often raised in the context of personal data. Social networks mining user information to target adverts, for example. This prompts discussion around how to put people back in control of their own data as well as encouraging individuals to be more aware of their data.
Apart from social networks, other examples of data asymmetry that relate to personal data include:
- Smart meters that provide you with a personal view of your energy consumption, whilst providing energy companies with an aggregated view of consumption patterns across all consumers
- Health devices that track and report on fitness and diet, whilst developing aggregated views of health across its population of users
- Activity loggers like Strava that allow you to record your individual rides, whilst developing an understanding of mobility and usage of transport networks across a larger population
But because asymmetry is so prevalent it occurs in many other areas; it’s not an issue that is specific to personal data. Any organisation that offers a B2B digital service will also be involved in data asymmetry. Examples include:
- Accounting packages that allow better access to business information, whilst simultaneously creating a rich set of benchmarking data on organisations across an industry
- Open data portals that will have metrics and usage data on how users of the service are finding and consuming data
- “Sharing economy” platforms that can turn individual transactions into analytics products
Data asymmetry is as important an issue in this areas as it is for personal data. These asymmetries can create power imbalances in sharing economy platforms like Uber. The impact of information asymmetry on markets has been understood since the 1970s.
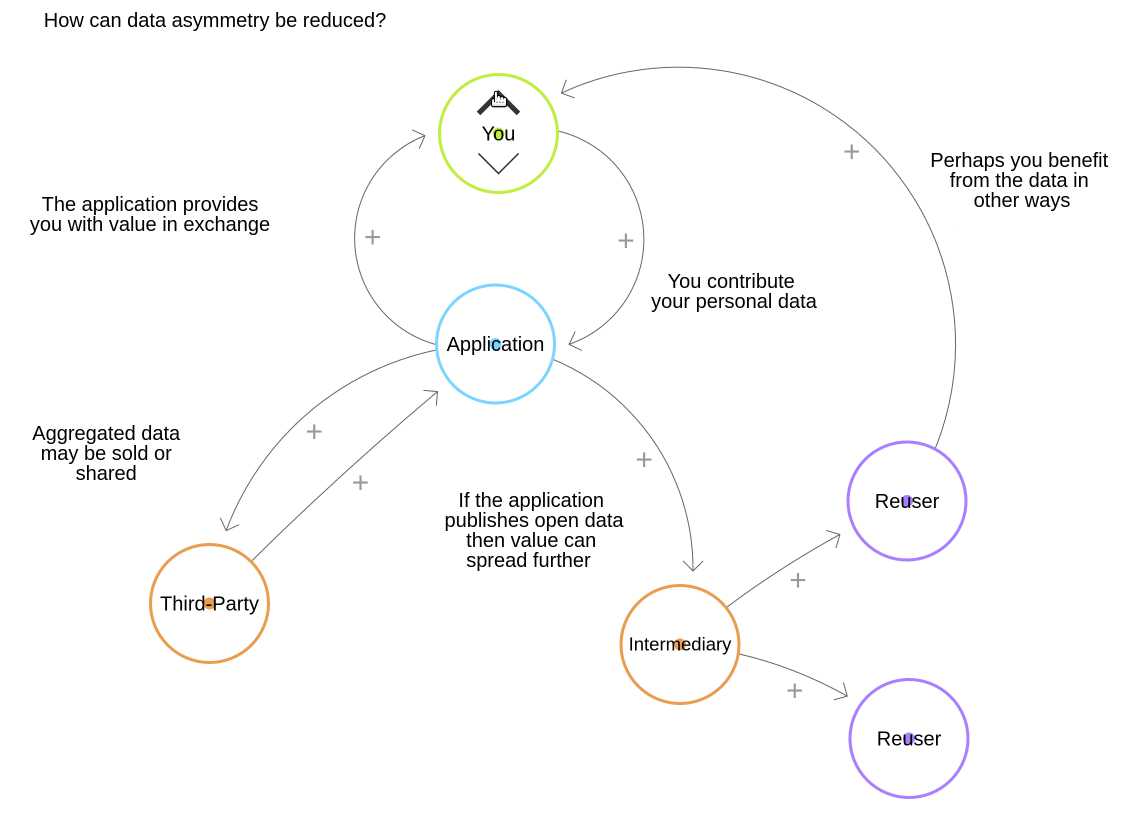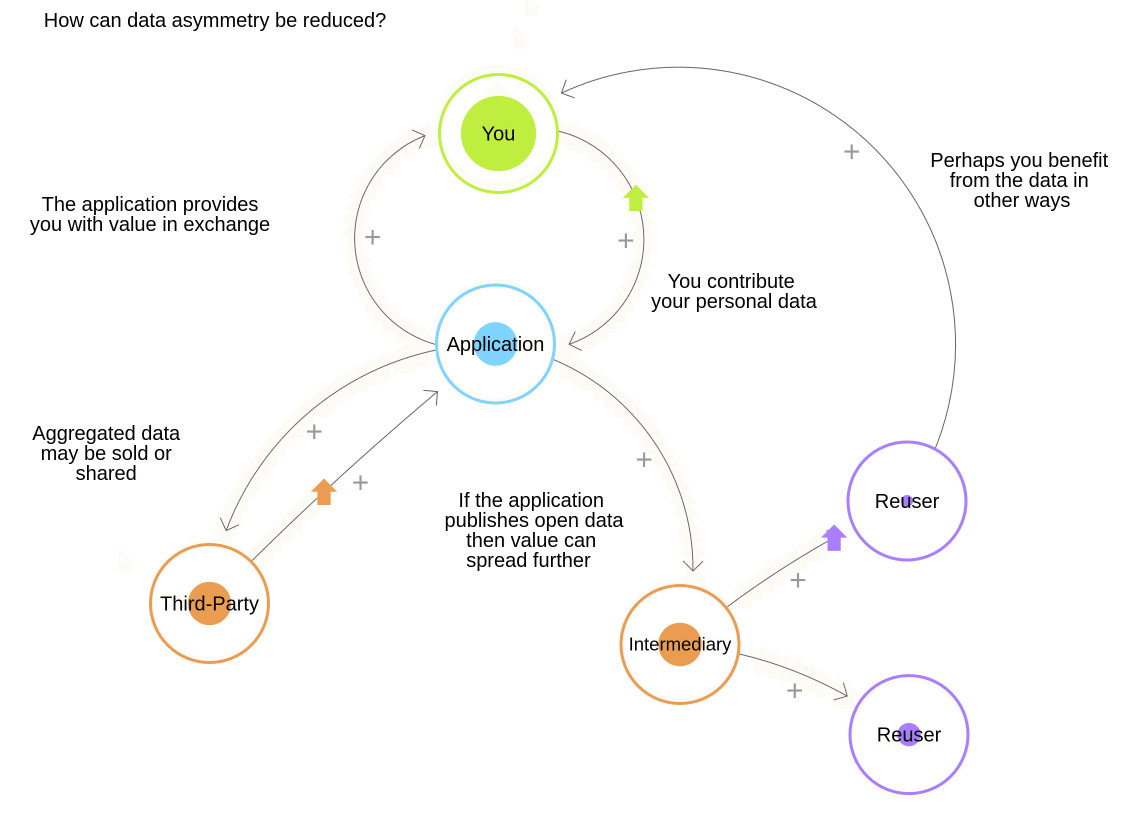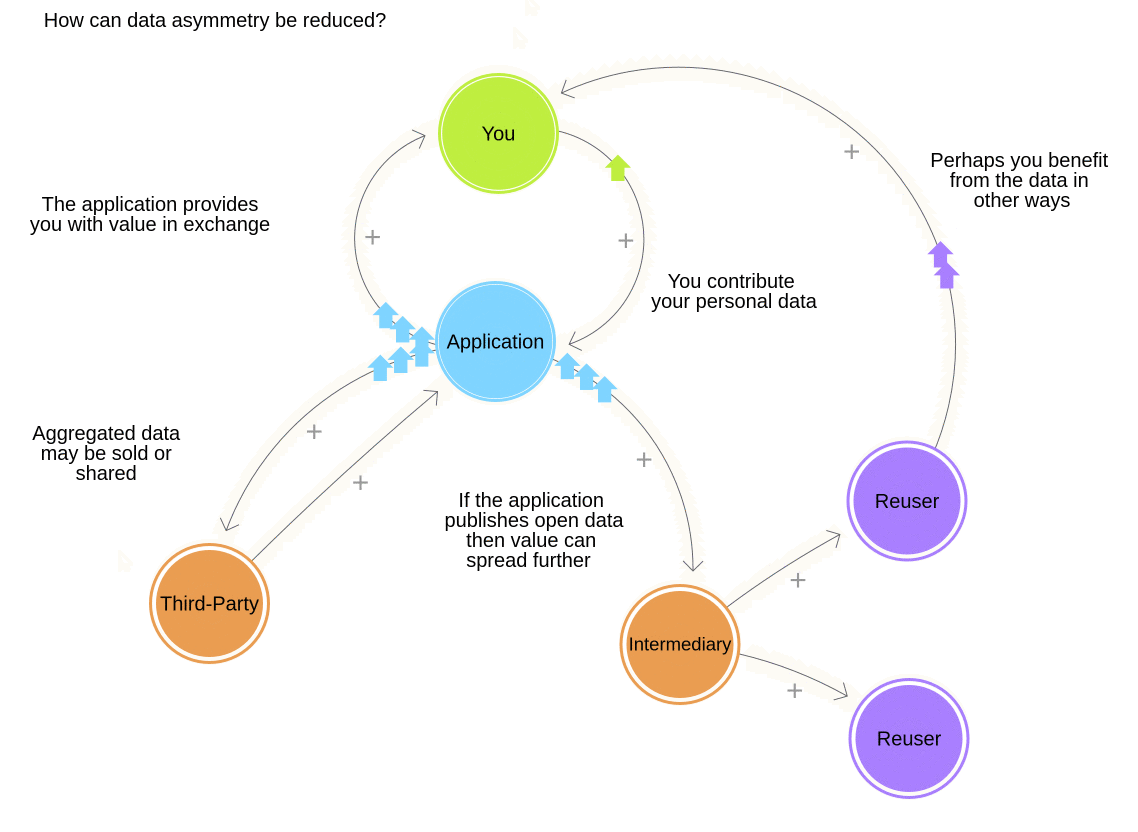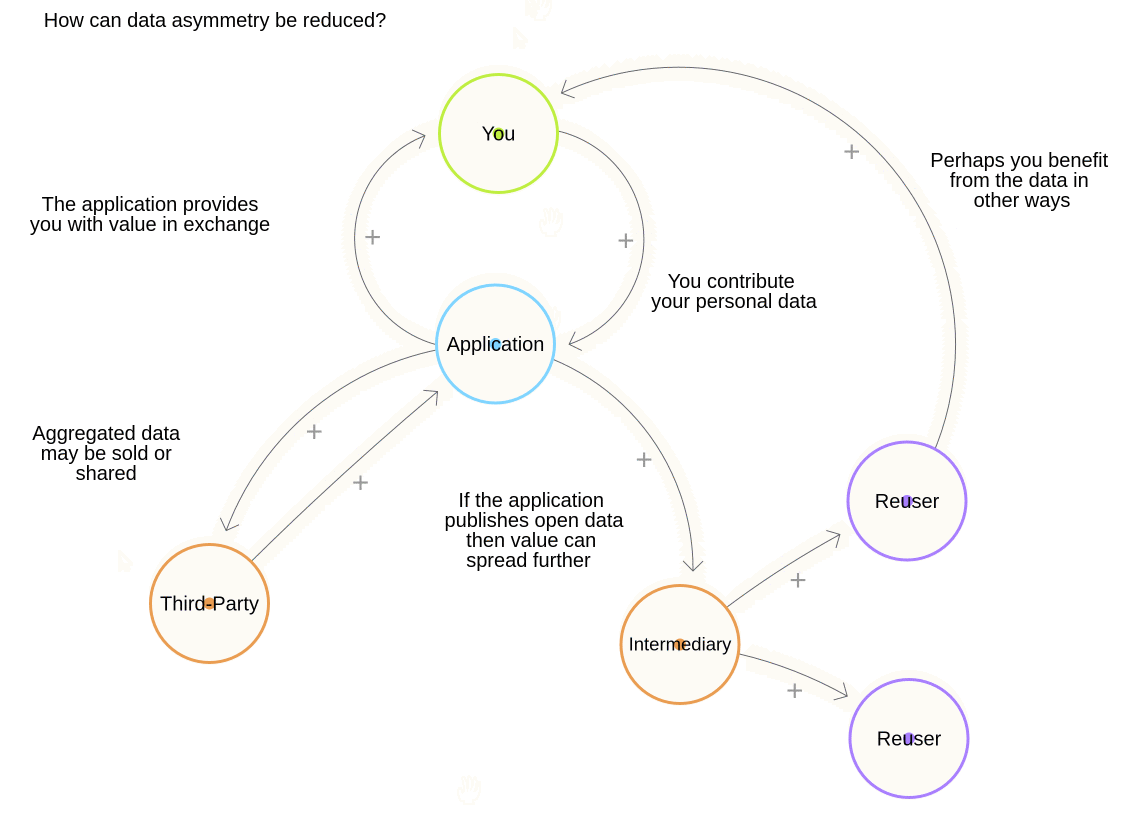
How can data asymmetry be reduced?
There are many ways that data asymmetry can be reduced. Broadly, the solutions either involve reducing disparity in access to data, or in reducing disparities in the ability to extract value from that data.
Reducing the amount of data available to an application or service provider is where data protection legislation has a role to play. For example, data protection law places limits on what personal data companies can collect, store and share. Other examples of reducing disparities in access to data include:
- Allowing users to opt-out of providing certain information
- Allowing users to remove their data from a service
- Creating data retention policies to reduce accumulation of data
Practising Datensparsamkeit reduces risks and imbalances associated with unfettered collection of data.
Reducing disparities in the ability to extract value from data can include:
- Giving users more insight and input into when and where their data is used or shared
- Giving users or businesses access to all of their data, e.g. a complete transaction history or a set of usage statistics, so they can attempt to draw additional value from it
- Publishing some or all of the aggregated data as open data
Different applications and services will adopt a different mix of strategies. This will require balancing the interests of everyone involved in the value exchange. Policy makers and regulators also have a role to play in creating a level playing field.
Update: the diagrams in this post were made with a service called LOOPY. You can customise the diagrams and play with the systems yourself. Here’s the first diagram visualising data asymmetry and here is the revised version shows how open data reduces asymmetry by allowing value to spread further.
This post is part of a series called “basic questions about data“.

One thought on “What is data asymmetry?”
Comments are closed.