All research looking at data ecosystems and infrastructure will consistently produce the same insight: we need better standards.
Data is never in the ideal shape or format for all of the analyses that people might want to do. Standards can help to reduce this friction. So most projects inevitably end up with a recommendation to create more standards, or drive adoption of existing standards.
But standards take time to create. To be successful, they need to be run through a well-defined, formal process. They need to be properly scoped and grounded in real use cases. They needed to be test, revised and then supported to drive adoption. And you may need a whole range of standards to address the different use cases required by different types of reuser.
This all takes time, money and a significant level of community buy-in and support.
Without those resources at hand, it may not be the right time to create new standards. But that doesn’t mean we can’t try to improve how data is published in the shorter term.
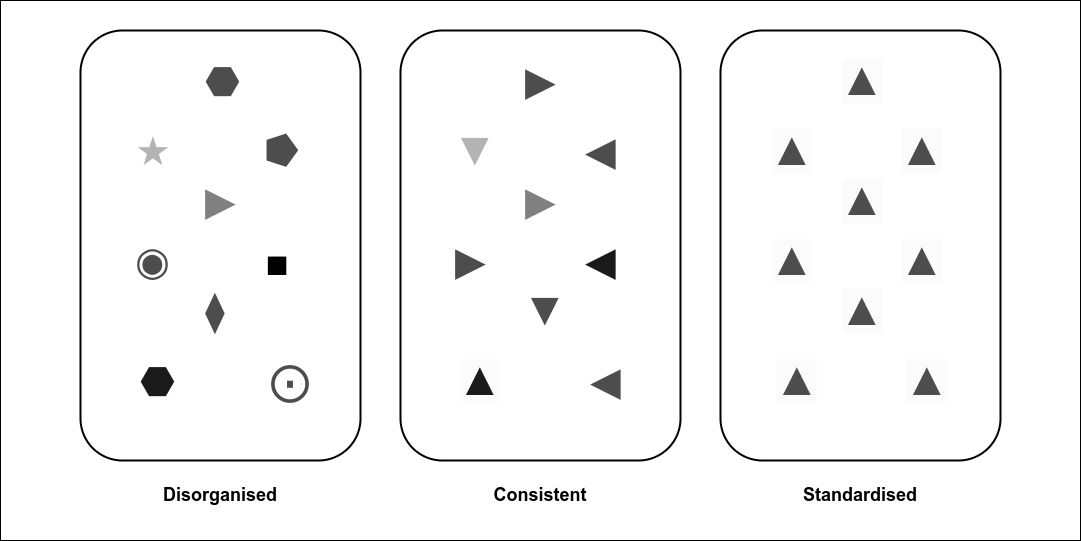
Before creating new standards we can instead look for ways to increase consistency in how data is published.
We might do this by encouraging use of the same licences to make it easier to combine datasets. Or by agreeing to use same set of file formats (CSV, JSON); designing CSV files in more consistent ways, publishing similar levels of detail, standardising metadata, etc.
While I see many projects encouraging use of the same licences and standardised metadata, I think it’s less common to see people recommending other ways to increase consistency across datasets.
These smaller changes may be easier to achieve and implement in the short-term. So the value of increasing consistency can be felt quicker. This can lead to short-term impact which can drive engagement for wider scale standards processes.
The work of finding the consistencies and inconsistencies across existing datasets is a necessary part of doing standards work. So it’s worth seeing if there are some quick wins to be hand. There’s no effort wasted.
With increased consistency it also becomes easier to make a case for standardisation to remove any remaining friction in accessing, using and sharing data.
For example, in the area I’m working currently there are many different but very similar formats for half-hourly energy data. This is ripe for standardising.
So before jumping into standards processes we should always consider other ways to encourage consistency across datasets.

2 thoughts on “Consistency before standards”
Comments are closed.