Identifiers are part of data infrastructure. They play an important role, helping to publish, structure and link together data. Identifiers are boundary objects, that cross communities. That means they need to be well-documented in order to be most useful.
Understanding how identifiers are created, assigned and governed can help us think through how to strengthen our data infrastructure. With that in mind, let’s take a quick tour of how different communities and systems have created identifier systems to help to uniquely refer to different digital and physical objects.
The simplest way to generate identifiers is by a serial number. A steadily increasing number that is assigned to whatever you need to identify next. This is the approached used in most internal databases as well as some commonly encountered public identifiers.
For example the Ordnance Survey TOID identifier is a serial number that looks like this: osgb1000006032892. UPRNs are similar.
Serial numbers work well when you have a single organisation and/or system generating the identifiers. They’re simple to implement, but can have their downsides, especially when they’re shared with others.
Some serial numbering systems include built in error-checking to deal with copying errors, using a check digit. Examples include the CAS registry number for identifying chemicals, and the basic form of the ISSN for identifying academic journals.


As we can see in the bar code form of the ISSN shown above, identifiers often have more structure to them. And they may not be assigned as a simple serial number.
The second way of providing unique identifiers is using a name or code. These are typically still assigned by a central authority, sometimes known as a registration agency, but they are constructed in different ways.
Identifiers for geographic locations typically rely on administrative regions or other areas to help structure identifiers. For example the statistics community in the EU created the NUTS codes to help identify country sub-divisions in statistical datasets. These are assigned based on hierarchy beginning with the country and then smaller geographic regions. Bath is UKK12 for example.
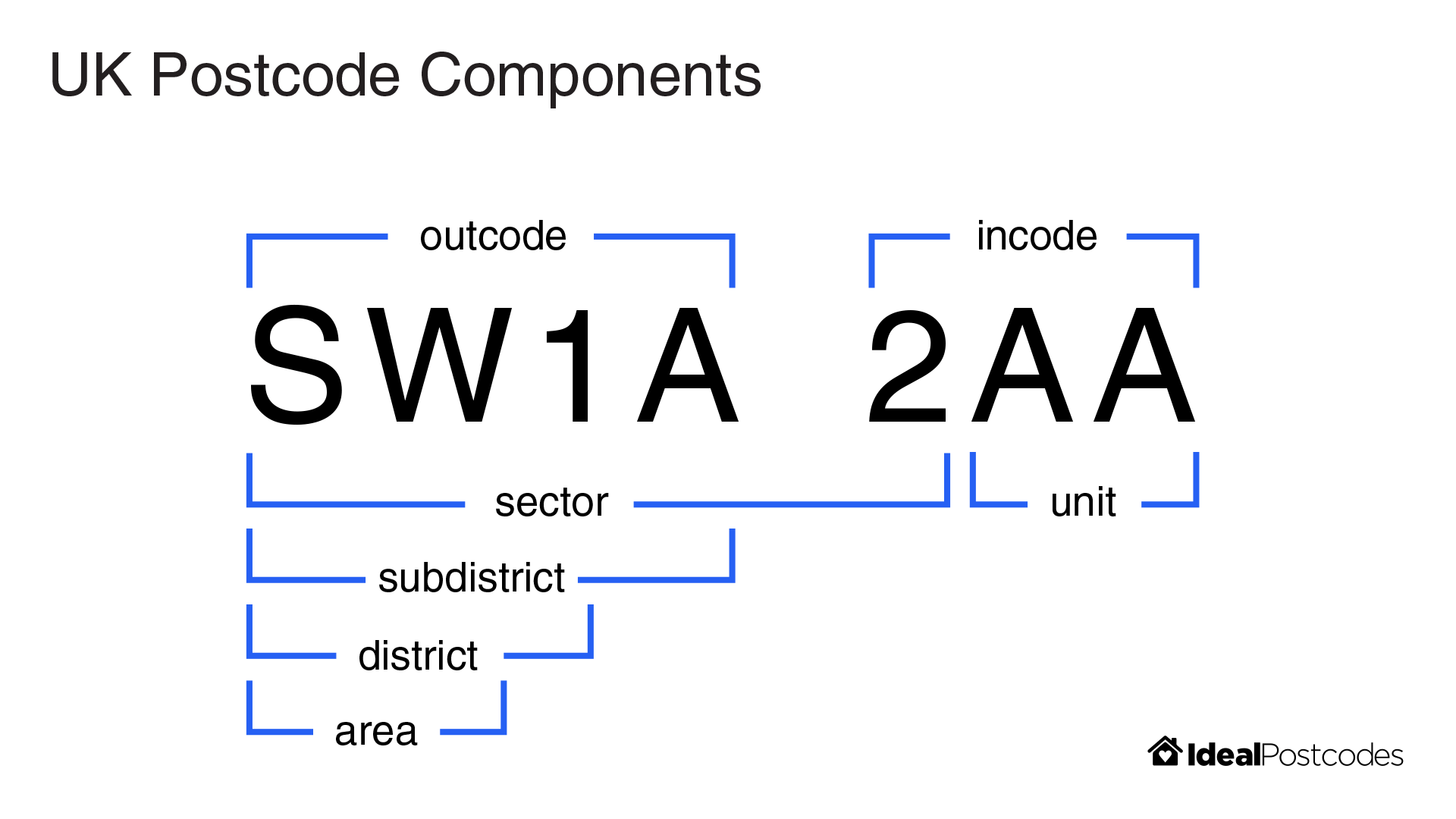
Postal codes are another geographically based set of codes. Both the UK and US postal codes use a geographical hierarchy. Only here the regions are those meaningful to how the Royal Mail and USPS manages its delivery operations, rather than being administratively defined by the government.

Hierarchies that are based on geography and/or organisational structures are common patterns in identifiers. Existing hierarchies provide a handy way to partition up sets of things for identification purposes.
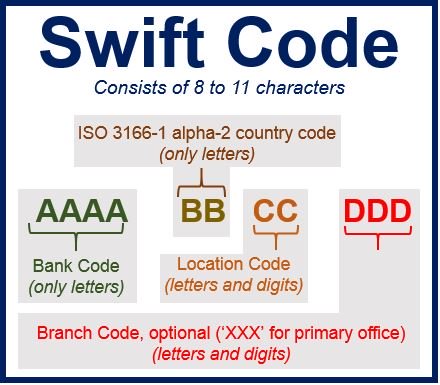
The SWIFT code used in banking has a mixture of organisational and geographic hierarchies.
Encoding information about geography and hierarchy within codes can be useful. It can make them easier to validate. It also mean you can also manipulate them, e.g. by truncation, to find the identifiers for broader regions.
But encoding lots of information in identifiers also has its downsides. The main one being dealing with changes to administrative areas that mean the hierarchy has changed. Do you reassign all the identifiers?
Assigning identifiers from a single, central authority isn’t always ideal. It can add coordination overhead which can be particularly problematic if you need to assign lots of identifiers quickly. So some identifier systems look at reducing the burden on that central authority.
A solution to this is to delegate identifier assignment to other organisations. There are two ways this is done in practice.
The first is what we might call federated assignment. This is where the registration agency shares the work of assigning identifiers with other organisations. A typical approach is to delegate the work of registration and assignment to national organisations. Although other approaches are possible.
The delegation of work might be handled entirely “behind the scenes” as an operational approach. But sometimes it ends up being a feature of the identifier system.
For example the (LEI) uses federated assignment where “Local Operating Units” do the work of assigning identifiers with. As you can see below, the identifiers for the LOUs become part of the identifiers they assign.

The International Standard Recording Code uses a similar approach with national agencies assigning identifiers.

Another approach to reducing dependence on, and coordination with a single registration agency, is to use what I’ll call “local assignment“. In this approach individual organisations are empowered to assign identifiers as they need them.
A simplistic approach to local assignment is “block allocation“: handing out blocks of pregenerated identifiers to organisations which can locally assign them. Blocks of IP addresses are handed out to Internet Service Providers. Similarly, blocks of UPRNs are handed out to local authorities.
Here the registration agency still generates the identifiers, but the assignment of identifier to “thing” is done locally. And, in the second case at least, a record of this assignment will still be shared with the agency.
A more common approach is to use “prefix allocation“. In this approach the registration agency assigns individual organisations a prefix within the identifier system. The organisation then generates new unique identifiers by combining their prefix with a locally generated suffix.
A suffix might be generated by adding a local serial number to the prefix. Or by some other approach. Again, after generating and assigning an identifier they are commonly still centrally registered.
Many identifiers use this approach. The EIDR identifiers used in the entertainment industry look like this:

A GTIN looks like this:

And the BIC code for shipping contains look like this:

One challenge with prefix allocation is ensuring that the rules for locally assigned suffixes work in every context where the identifier needs to appear. This typically means providing some rules about how suffixes are constructed.
The DOI system encountered problems because publishers were generating identifiers that didn’t work well when DOIs were expressed as URLs, due to the need for extra encoding. This made them tricky to work with.
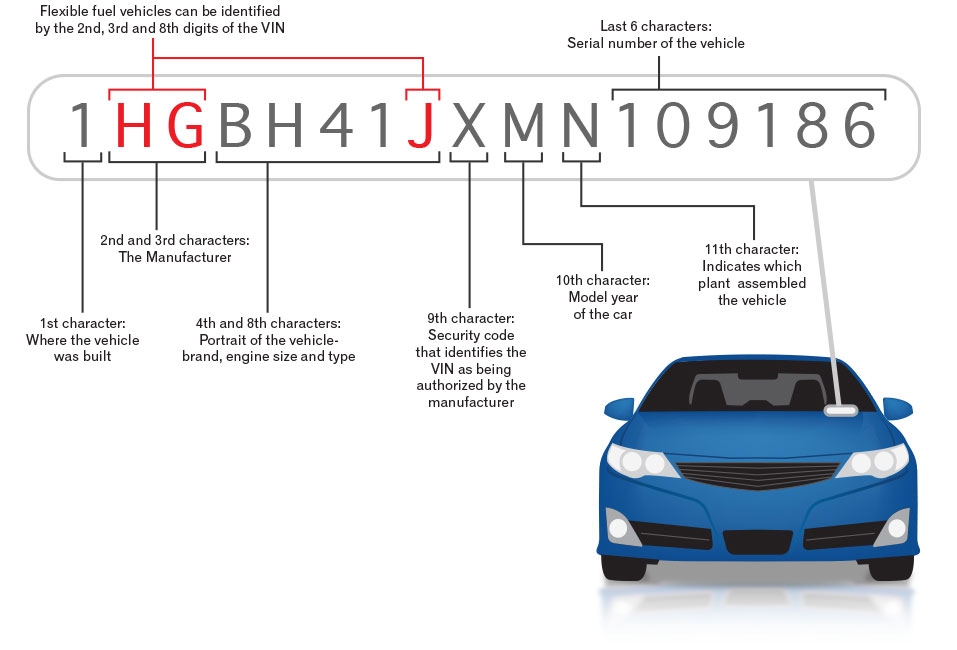
For a complicated example that mixes use of prefixes, country codes and check digits, then we can look at the VIN, which is a unique identifier for vehicles. This 17 digit code includes multiple segments but there are four competing standards for what the segments mean. Sigh.
It’s possible to go further than just reducing dependency on registration agencies. They can be eliminated completely.
In distributed assignment of identifiers, anyone can create an identifier. Rather than requesting an identifier, or a prefix from a registration agency, these systems operate by agreeing rules for how unique identifiers can be constructed.
One approach to distributed assignment is to use an element of randomness to generate a unique identifier at the point of time its needed. The goal is to design an algorithm that uses a random number generator and sometimes additional information like a timestamp or a MAC address, to construct an identifier where there is an extremely low chance that someone could have created the same identifier at the same moment in time. (Known as a “collision”).
This is how UUIDs work. You can play with generating some using online tools.
Identifiers like UUIDs are cheap to generate and require no coordination beyond an agreed algorithm. They work very well when you just need a reliable way to assign an identifier to something with reasonable confidence that if our data is later combined then we won’t encounter any issues.
But what if we need to independently assign an identifier to the same thing? So that when we later combine our datasets, then our data will link up?
For this we need to use a hash-based identifier. A hash based identifier takes some properties of the thing we want to identify and then use that to construct an identifier. If we have a good enough algorithm then even if we do this independently we should end up constructing the same identifier.
This is sometimes referred to as creating a “digital fingerprint” of the object. It’s commonly used to identify copies of objects. For example, the approach is used to construct content identifiers in the IPFS system. And as part of YouTube’s Content ID system to manage copyright claims.
But hash-based identifiers don’t have to be used for managing content, they can be used as pure identifiers. The most complex example I’m familiar with is the InChi, which is a means of generating a unique identifier for chemicals by using information about their structure.

By using a consistent algorithm provided as open source software, chemists can reliably create identifiers for the same structures.
The SICI code used to identify academic papers was a hash based system that used metadata about the publication to generate an identifier. However in practice it was difficult to work with due to the variety of ways in which content was actually published and the variety of contexts in which identifiers needed to be generated.
Hash-based identifiers are very tricky to get right as you need a robust algorithm, that is widely adopted. Those needing to generate identifiers will also need to be able to reliably access all of the information required to create the identifier. Variations in availability of metadata, object formats, etc can all impact how well they work in practice.
