
One of the things that has interested me for some time now is how RDF and Linked Data enables communities to enrich information published by organizations, e.g. by annotating it with additional properties and relationships (links). This is after all, one of the intended goals of the technology: to make it easier for people to converge on common names for things and collectively share data about those things.
The ability to publish URIs for things, and then have those URIs decorated by a motivated community with additional metadata, provides organizations with an interesting way to take advantage of Linked Data. The enriched data can be reused by the organization to improve its own datasets and used to drive improved processes, new product development, etc.
The interesting angle is that while both the organization and the community directly benefits from the sharing (both gain access to data they wouldn’t have normally, or at least without extra expense) there are some asymmetries in the relationship. Specifically, an organization worried about its brand is likely to have higher, or at least different, standards for reliability and quality than its community; especially so it we consider only the non-commercial users in that community. Before the organization may ingest and republish this data (e.g. on its website) then those standards and a certain amount of filtering may need to be applied.
I like to think of these contributions as being in a “liminal zone” between the authoritative content that is completely owned and managed by the publisher and the stuff that exists out there on the Wild Wild Web which is only tangentially related (at best). There’s a zone of transition between the two spaces, where the data and the URIs start out being owned by the publisher then embraced, adopted (and even co-opted) by a community. A user may want to freely navigate between these different areas and apply their own rules about quality, reliability or general bozo filtering. And they can end up in a very different space to where they started. An organization may want to act quite differently; in terms of what and how much they fetch, and how they use what data they collect.
The following diagram attempts to sketch out this liminal zone from the perspective of the BBC.
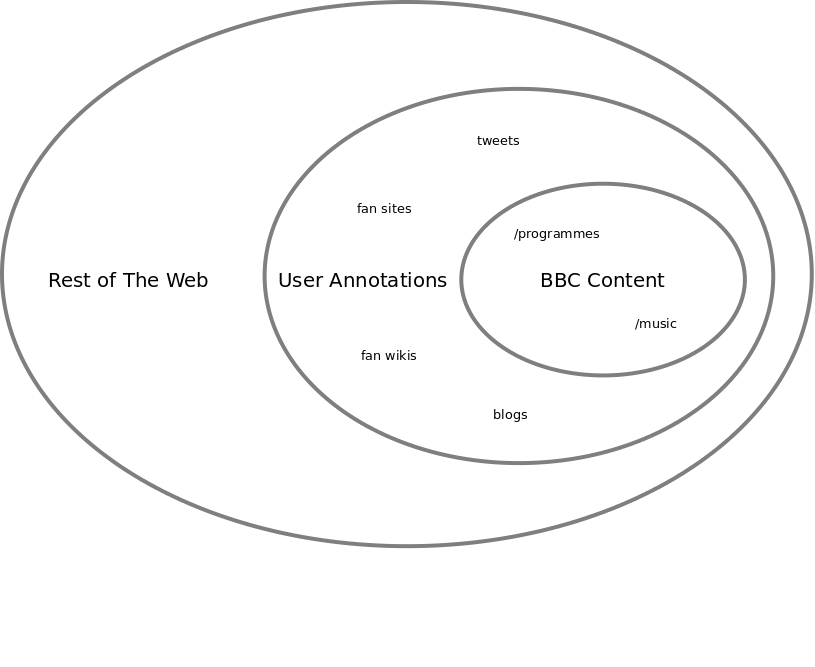
Its the user annotations that annotate or relate to the BBC URIs that form the liminal zone between the authoritative publisher-sourced data, and the rest of the content on the web. You could put almost any organization into that central space and the same relationship would hold. Its the strong identifiers associated with Linked Data that connects up the internal and external views of the data.
I recently commissioned a project at Talis called Fanhu.bz which aims to help surface content and contributions that exist in this liminal zone. I see it as a first step towards exploring some of these subtle data sharing issues. Mapping out the fringes of Linked Data sets, as exemplified by BBC Programmes and Music, and then exploring how that data can be remixed and reused not only by the community but also by the publisher themselves, is an attempt to explore models for consuming Linked Data that goes beyond simple re-publishing and visualisation. The technology has a lot more to offer. And when we talk about “Linked Data for the Enterprise” I think we need to be thinking beyond just internal data integration.
